
1. 머신러닝 학습 알고리즘의 구현
학습이라는 것은 매우 많은 기간 동안 연구의 문제였습니다. 인간의 기본적인 생존 기술부터 고급 추상적인 주제까지 새로운 지식을 얻는 방법을 컴퓨터 세상에서 이해하고 재현하는 것은 어렵습니다. 기계는 예제를 비교하고, 그것들 중에 유사성을 발견함으로써 학습합니다.
기계(그리고 또한 인간을 위해)와 인간이 배우는 가장 쉬운 방법은 해결해야 하는 문제를 단순화하는 것입니다. 모델이라고 하는 것은 현실의 단순화된 버전이며, 이 작업에 대해 유용합니다. 연구해야 되는 관련 문제 중 일부는 최소 샘플 수, 과소적합 underfitting 및 과대 적합overfitting 과 그와 관련된 특성과 이를 모델이 어떻게 잘 학습할 수 있는 지입니다. 서로 다른 유형의 목표 변수에는 다른 알고리즘이 필요합니다.
이 장에서는 다음의 주제를 다룹니다:
-
학습 및 모델의 이해
-
모델 특성에 집중
-
실제 머신러닝 모델의 학습
-
모델 평가
학습 및 모델의 이해
인간이 배우는 방식은 수십년 동안 연구되어 왔습니다. 우리가 알고 있는 것을 완전히 새로운 시나리오에 적용하기 위해, 지식을 습득하고, 그것을 사용하고 일반화하는 방법을 설명하려고 하는 소수의 심리학 이론이 있습니다. 한걸음 물러나서 자신에게 물을 수 있습니다: 배운다는 것은 무엇을 의미합니까? 우리는 일단 무언가를 배운 후에는 좀더 또는 덜 자세한 방법으로 반복할 수 있다고 말할 수 있습니다. 실제로, 학습이라는 것은 단순히 행동을 복사하거나 시를 암기하는 것 이상의 것을 의미합니다. 실제로, 우리는 배우는 것을 이해하고, 그 지식을 일반화할 수 있으며, 이를 통해 새로운 사람들, 장소 및 상황에 올바르게 대응하는데 도움이 됩니다.
인간의 행동과 지능을 모방하는 무언가의 기계를 만들고자 하는 바람은 매우 오랫동안 있었습니다. 수 백년 전에, 왕들은 체스 게임 기계, 인간 연주가가 필요하지 않은 음악적 도구, 그리고 모든 종류의 질문에 대답하는 신기한 상자에 놀랐습니다. 이러한 많은 위조된 발명품들은 인간의 가장 큰 꿈의 하나가 지능을 창조하는 것이며, 지능이 애매하고 정의하기 어려운 때조차도 사람들이 일반적으로 수행하는 쉽고 어려운 작업을 복제할 수 있음을 보여주어 왔습니다.
오랜 세월이 흐르면서, 기술은 이제 최소한 생각하게 보이는 수준의 기계를 만들 수 있는 방식으로 진화되어 왔습니다. 실제로 우리가 지능이라고 부르는 대부분의 시스템은 반복적인 작업을 수행하거나 예제의 방식에 따라 그것들을 보여준 것에 따라서 외부 입력에 단지 반응할 수 있습니다. 이 장을 진행하면서, 인간의 학습과 지능의 정의된 특성 중 일부는 이미 현대 머신러닝 시스템의 일부이며, 또 다른 일부는 여전히 공상과학 소설의 주제입니다.
정의에 따르면, 머신러닝은 기계 또는 알고리즘을 업무를 수행하는 것을 가르친다는 것을 의미합니다. 우리는 지금 이 것을 수 년 동안 수행해 왔으며 이를 프로그래밍이라고 합니다. 우리는 컴퓨터에게 일련의 명령, 실행 순서 및 제안된 수의 입력에 반응하는 방법에 대한 여러 옵션을 제공합니다. 입력을 알 수 없거나, 컴퓨터가 프로그램에 포함되지 않은 작업을 수행하도록 요청받으면 오류가 보여주고 실패합니다. 이 전통적인 패러다임과 머신러닝의 차이점은 컴퓨터에게 정확히 무엇을 해야 하는지 알려주지 않는다는 것입니다. 우리는 패턴을 발견하도록 하거나 원하는 샘플을 보여주도록 하게 할 것입니다. 물론 프로그래밍은 사용되지만 앞에서 설명한 의미에서 학습하는 알고리즘을 정의하기 위해 사용합니다. 일련의 점들을 더 잘 대표하는 직선을 찾는 것부터 자동차를 운전하는 것까지, 기계가 할 수 있는 모든 것이 이런 식으로 배웁니다.
어린아이로서 우리는 주변 세계를 탐험하기 시작합니다. 우리는 어릴 때 단어나 예제를 이해하기 어려우므로, 기본적으로 감각을 통해 세상을 경험합니다. 우리는 단단하고 부드러운 것, 거칠고 매끄러운 것, 뜨겁고 차가운 것들 간의 차이를 배웁니다. 우리는 무언가가 필요할 때 주의를 기울일 수 있으며, 부모와 애완 동물의 인내심 수준을 이해할 수도 있습니다. 대부분의 경우, 어느 누구도 우리 옆에 앉아서 우리가 어떻게 보고, 듣고, 느끼고, 맛보고, 냄새 맡는 지를 설명하지 않습니다. 이것을 우리는 비지도 학습unsupervised learning이라고 부르는 것의 예입니다.
비지도 학습에서 훈련 데이터training data는 레이블이 없습니다. 우리의 도움이나 개입없이, 알고리즘(또는 프로그램)이 데이터에서 필요한 연결 또는 알지 못하는 패턴을 찾고 데이터 세트의 세부 사항과 속성을 학습합니다. 나중에 우리는 자라면서, 단어를 이해하고 물건에 이름을 부르기 시작합니다. 부모는 우리가 개나 고양이를 볼 때, 이름과 그것들에 대해 배우고, 우리는 다른 아이들의 장난감 중에서 우리의 장난감을 식별하는 법을 배웁니다(그들과 싸우기도 하고). 그것을 깨닫지 않고도 우리는 사물, 동물 및 사람들의 일부 특성을 그것들의 이름을 관련시킵니다. 이것들이 지도 학습supervised learning이라고 알려진 것들의 예입니다. 컴퓨터의 경우에는 알고리즘이 문제의 속성을 대표하는 변수 집합으로 표시되며 그러면 이러한 특성이 레이블 이름과 어떤 관련이 있는지를 학습합니다.
과학은 우리를 둘러싼 세상의 엄청난 복잡성에 대해 보여주었습니다. 모든 과학 지식 분야에는 고급 수학적 계산과 데이터를 보는 완전히 새로운 방법이 필요합니다. 그러나 우리가 설명할 수 있는 대부분은 실제 세계의 일부일 뿐입니다. 우리는 물리적인 현상, 경제 또는 금융 사건을 묘사하거나 개인과 그룹의 행동을 이해하려고 할 때마다, 실제 문제의 단순화된 버전에 의존합니다. 이것을 모델이라고 하며 우리가 설명하고자 하는 것의 심적 표상mental representation을 만들 수 있게 합니다. 모델이 충분히 정확하면, 향후 사건을 예측하거나 특정 결과에 대한 대략적인 가치를 얻을 수 있습니다. 지금까지 이해했겠지만 이것은 매우 강력합니다. 예를 들어, 포병이 대포가 맞히는 정확한 정밀도를 계산할 수 있다면, 그의 군대는 전투에서 적보다 분명한 이점을 갖습니다. 모델은 문제를 이해하고 결국 예측하는 데 사용되는 단순화된 버전의 현실입니다. 상대방이 무시하는 무언가를 이해하는 것은 항상 유리하게 작용합니다.
예제로 학습 – 선형회귀 모형linear regression model
당신과 친구가 작은 아이스크림 가게를 소유하고 있다고 상상해 보십시오. 당신은 매일 몇 킬로그램(kg)의 아이스크림을 만들 지를 논의하고 있으며 날씨가 더 뜨거울수록 더 많은 아이스크림이 팔릴 것이라는 데에 서로 동의하였습니다. 이것만이 고려해야 할 유일한 요소는 아니고 판매 수에 영향을 줄 수 있는 다른 변수도 분명히 존재합니다. 합리적인 사람과 훌륭한 분석가로서, 상점 영업 시간 동안의 평균 온도와 판매되는 아이스크림의 양을 기록하는 작은 실험을 실시하기로 결정했습니다. 여름은 특히 비가 오는 등 온도 변화가 높기 때문에 변수에 대한 좋은 범위를 획득하는 데 도움이 됩니다. 최종 데이터 세트는 다음 표와 같습니다.
|
평균 온도(℃) |
팔린 아이스크림(kg) |
|
26 |
45 |
|
23 |
42.5 |
|
29 |
53.5 |
|
23 |
35.5 |
|
15 |
32.5 |
|
19 |
34.5 |
|
21 |
33.5 |
|
18 |
35 |
|
15 |
32.5 |
|
25 |
40.5 |
|
25 |
39.5 |
|
16 |
32 |
|
23 |
44.5 |
|
23 |
39.5 |
|
20 |
33 |
|
17 |
26.5 |
|
21 |
37.5 |
|
29 |
49.5 |
|
25 |
40.5 |
|
24 |
44 |
이 모델은 판매된 아이스크림의 양을 (직접적으로) 평균 온도에 비례한다고 나타냅니다. 이 가설을 테스트하기 위해 수집된 데이터를 통해 산점도scatter plot를 만들 수 있습니다.
-
표를 포함한 셀의 전체 범위를 선택하고, 삽입 메뉴Insert menu를 클릭하고, 챠트Charts를 선택하십시오.

-
그리고, 분산형Scatter을 글릭하면 다음과 같이 나옵니다.
축 제목의 이름을 쓰면, 다음의 챠트와 유사한 챠트가 나타납니다:
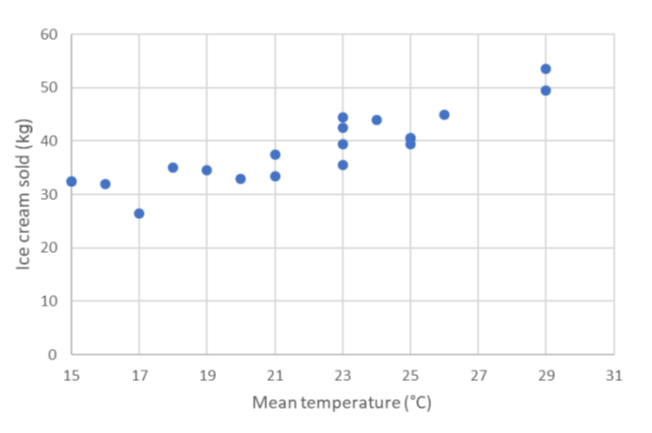
우리는 실제로 선형적인 상관 관계가 있고 그것이 양의 관계(온도의 값이 증가할 수록, 아이스크림이 더 많이 팔림)라는 것을 알 수 있습니다 그런 다음 다음과 같이 선형 방정식을 사용하여 모델을 나타낼 수 있습니다.
IC = a * T + b (1)
여기서 IC는 팔린 아이스크림의 양이고, T는 평균 온도, 그리고 a와 b는 선형회귀에 의해 계산된 상수입니다.
a와 b의 값을 구하기 위해 Excel의 분석도구를 추가해서 이러한 기능을 사용할 수 있습니다. 활성화하지 않은 경우 아래의 링크를 통해 수행 방법에 대한 지침을 참조하십시오.
https://support.office.com/en-ie/article/use-the-analysis-toolpak-to-perform-complex-data-analysis-6c67ccf0-f4a9-487c-8dec-bdb5a2cefab6
-
워크시트에서 데이터 범위를 선택하고, 리본 메뉴의 데이터Data로 가서 데이터 분석Data Analysis을 선택하십시오.

-
팝업 메뉴pop-up menu에서 회귀분석Regression을 선택하고, 확인을 누르십시오
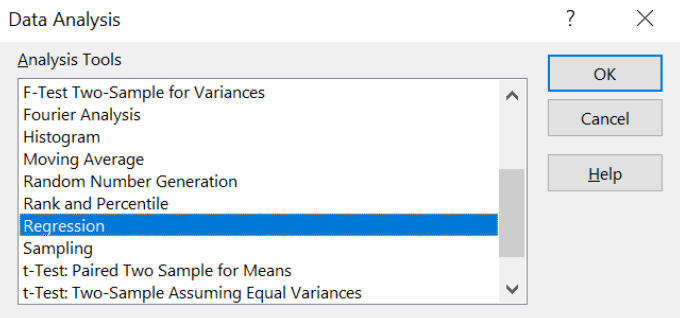
-
x와 y 범위가 올바른지 확인하십시오(x는 평균 온도이고 y는 아이스크림 양). 선적합도Line Fit Plots를 선택하면 새로운 다이어그램에서 데이터 점들 위에 회귀선을 볼 수 있습니다.
결과를 보면, 데이터에 가장 잘 적합한 선을 다음과 같이 표시할 수 있습니다:
IC = 1.5* T + 6 (2)
a의 ±0.2 및 b의 ±4에 대한 표준오차가 있습니다. R2 값은 0.78이므로 적합 결과가 매우 좋지는 않으며 아이스크림 판매 변동의 78%만 평균 온도로 설명할 수 있습니다. 그러므로 당신과 당신의 친구는 모두 옳았습니다!
다음 다이어그램은 적합선을 보여줍니다.
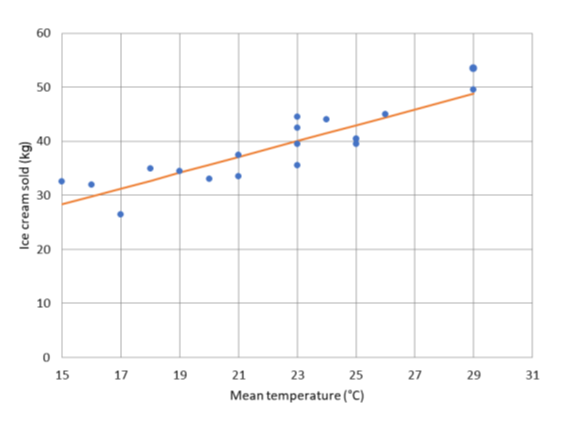
직선이 데이터를 잘 나타내는 것은 분명하지만 일부 점들은 약간 떨어져서 아이스크림 소비를 예측할 때 다른 요소를 고려할 필요가 있다는 것을 보여줍니다. 어쨌든 하루 동안의 평균 예측 온도가 주어지면 방정식 (2)를 사용하여 가능한 수요를 충당하기 위해 얼마나 많은 아이스크림을 만들 것인지 대략적인 추정을 할 수 있습니다.
선형회귀의 나머지 결과는 다음 섹션에서 그것들의 몇 가지를 사용할 것이므로 그대로 유지하십시오.
모델 특성에 집중Focusing on model features
현실의 단순화된 대표로써, 모델은 우리가 표현하고자 하는 문제의 다른 부분을 설명하는 관련 정보를 포함하는 변수의 집합도 포함합니다. 이 변수는 앞의 예에서 보았 듯이 1kg의 아이스크림처럼 구체적이거나 텍스트 문서에서 두 단어의 의미가 얼마나 유사한 지를 나타내는 숫자적인 값처럼 추상적일 수 있습니다.
머신러닝 모델의 특별한 경우에는 이러한 변수들을 특성features이라고 합니다. 우리가 설명하거나 예측하려는 현상에 대한 관련 정보를 제공하는 유의한 특성을 선택하는 것이 가장 중요합니다. 비지도 학습을 고려할 경우, 적절한 특성은 데이터 집합에서 정보의 클러스터링 또는 연관성을 더 잘 나타내는 것들입니다. 지도 학습의 경우, 가장 중요한 특성은 목표 변수 – 즉 예측하거나 설명하기를 원하는 값 – 와 밀접한 관련이 있는 특성입니다.
머신러닝 모델에서 얻을 수 있는 통찰력의 품질은 모델에 대한 입력으로 사용되는 특성에 달려 있습니다. 특성 선택Feature selection 및 특성 엔지니어링feature engineering은 모델의 입력을 개선시키기 위해 일반적으로 사용되는 기술입니다. 특성 선택은 식별된 모델 구성에 사용하기 위해 관련 특성의 하위 집합을 선택하는 프로세스입니다. 변수 선택variable selection 또는 속성 선택attribute selection이라고도 합니다. 머신러닝 모델을 구축하는 동안, 특성 선택 및 데이터 정리data cleaning가 가장 우선적이며, 가장 중요한 단계입니다. 특성 엔지니어링은 식별된 데이터의 (컴퓨터) 특정 분야의 지식domain knowledge을 사용하여 머신러닝 알고리즘을 작동시키는 특성을 만들어 내는 프로세스로 정의됩니다. 이것이 올바르게 수행되면, 이러한 모델 또는 시스템에 공급되는 새로운 데이터에서 특성을 생성하여 머신러닝 알고리즘의 예측력을 증가시킬 것입니다.
이전 예에서 모델 특성은 평균 온도와 판매된 아이스크림의 양입니다. 우리는 이미 더 많은 변수가 관련되어 있음을 보여주었으므로, 매일 아이스크림 소비를 더 잘 설명하기 위해 몇 가지 특성을 추가할 수 있습니다. 예를 들어 데이터를 기록하고 있는 요일을 고려하여 이 정보를 다른 특성으로 포함시킬 수 있습니다. 추가적으로, 다른 관련된 정보는 다소 정확하게 특성으로 표현될 수 있습니다. 지도 학습에서는 입력 변수 특성features,과 목표 또는 예측 변수 레이블label을 사용하는 것이 일반적입니다.
특성은 숫자형numerical(예: 앞에 예처럼 온도) 또는 범주형categorical(예: 요일)일 수 있습니다. 컴퓨터에서 모든 것은 숫자 데이터로 표시되므로, 범주형 데이터는 범주를 숫자에 할당하여 숫자형으로 변환해야 합니다. one-hot encoding※은 범주형 변수를 머신러닝 알고리즘에 입력할 수 있도록 범주형 변수를 숫자 형식으로 변환(또는 부호화encorded)하는 프로세스입니다.
※ one-hot encoding: 단 하나의 값만 True이고 나머지는 모두 False인 인코딩을 의미하는 것으로 이 과정을 거치면 데이터 형태는 0-1로 이루어졌기 때문에 컴퓨터가 인식하고 학습하기에 용이함
다음의 예제와 같이, 요일을 요일 번호로 변환해 봅니다. (one-hot encoding은 아님)
|
요일 |
요일 번호 |
|
월요일 |
1 |
|
화요일 |
2 |
|
수요일 |
3 |
|
목요일 |
4 |
|
금요일 |
5 |
|
토요일 |
6 |
|
일요일 |
7 |
이 부호화encoding는 요일 순서를 반영하고, 주말에 가장 높은 값을 부여합니다.
판매하고 있는 각 맛에 대한 아이스크림의 양을 더 구체적으로 예측하기를 원한다고 가정해 봅시다. 편의상 초콜릿, 딸기, 레몬 및 바닐라의 네 가지 맛을 만들었다고 가정해 봅시다. 요일 부호화에서와 동일한 방식으로 각 맛에 하나의 숫자를 지정할 수 있습니까? 대답은 부정적입니다. 시도하고자 하는 이것에 대해 무엇이 잘못되었는지 보도록 합시다.
|
맛 |
맛의 번호 |
|
초콜릿 |
1 |
|
딸기 |
2 |
|
레몬 |
3 |
|
바닐라 |
4 |
이 부호화를 사용함으로써, 우리는 초콜릿이 바닐라보다 딸기에 더 가깝다는 것을 암시 적으로 말하고 있으며(1 unit 대비 3 unit) 이는 맛의 실제 속성은 아닙니다. 숫자로 변환하는 올바른 방법은 이진 변수binary variables를 만드는 것입니다. 이 방식은 one-hot encoding으로 알려져 있으며 다음 표와 같습니다.
|
구 분 |
초콜릿 여부 |
딸기 여부 |
레몬 여부 |
바닐라 여부 |
|
초콜릿 |
1 |
0 |
0 |
0 |
|
딸기 |
0 |
1 |
0 |
0 |
|
레몬 |
0 |
0 |
1 |
0 |
|
바닐라 |
0 |
0 |
0 |
1 |
이 방법은 원래 변수의 각각의 가능한 값마다 하나의 이진 변수를 작성하여 특성의 수를 증가시키기 때문에 약간의 간접비용overhead을 생성합니다. 긍정적인 측면에서는, 특성의 속성을 올바르게 계산한다는 겁니다. 다음 장에서 이에 대한 몇 가지 예를 살펴보겠습니다.
목표 변수의 유형에 따라, 회귀 모델regression models
(즉, 연속형 목표 변수) 또는 분류 모델classification models (즉, 이상형 목표 변수)로 구분할 수 있습니다. 예를 들어 실수 또는 정수를 예측하기 위해서는 회귀를 사용하지만, 한정된 수의 옵션이 있는 꼬리표tag를 예측하려는 경우 분류를 사용합니다.
실제 머신러닝 모델의 학습
우리는 이미 매우 간단한 예를 보았고 이것들을 기본적인 개념을 설명하는 데 사용했습니다. 다음 장에서는 보다 복잡한 모델을 살펴보겠습니다. 우리는 명확성을 위해 아주 작은 데이터 집합 및 쉬운 작업을 통한 머신러닝을 마스터하기 위한 여정을 시작하도록 제한했습니다. 실제의 문제를 해결하기 위해 머신러닝 모델로 작업할 때 알아야 할 몇 가지 일반적인 고려 사항이 있습니다:
-
데이터의 양이 매우 많습니다. 실제로, 더 큰 데이터 집합은 보다 정확한 모델과 보다 신뢰할만한 예측을 얻는 데 도움이 됩니다. 일반적으로 빅데이터라고 하는 극단적으로 큰 데이터 집합은 저장storage 및 조작manipulation 문제를 일으킬 수 있습니다.
-
데이터는 깨끗하게 정리되어 사용할 준비가 되어 있지 않으므로, 데이터 정리는 아주 중요하며 많은 시간이 걸립니다.
-
실제 세상의 문제를 올바르게 나타내는 데 필요한 특성의 건수가 보통 많습니다. 앞에서 언급한 특성 엔지니어링 기법은 손으로 수행할 수 없으므로 자동화된 방법을 고안하고 적용해야 합니다.
-
각 개별적인 특성의 유의성보다 입력 특성의 조합의 예측력을 평가하는 것이 훨씬 중요합니다. 특성을 선택하는 방법에 대한 간단한 예는 5장, 상관관계 및 변수의 중요성Correlations and the Importance of Variables에 나와 있습니다.
-
우리가 적용한 첫 번째 모델에서 좋은 결과를 얻지 못할 것입니다. 다양한 머신러닝 모델을 테스트하고 평가한다는 것은 동일한 단계를 여러 번 반복한다는 것을 의미하며 일반적으로 자동화도 필요합니다.
-
데이터 집합은 훈련training 목적(보통 80%)을 위해 데이터의 일부와 테스트를 위해 나머지 데이터를 사용할 수 있을 정도로 충분히 커야 합니다. 훈련 데이터에 대해서만 모델의 정확도를 평가하는 것은 잘못된 것입니다. 모델은 학습 데이터 세트를 설명하고 예측하는 데 매우 정확할 수 있지만, 이전에는 볼 수 없었던 새로운 데이터 값을 적용하는 경우 잘못된 결과를 일반화하고 전달하지 못할 수 있습니다.
-
훈련 및 테스트 데이터는 동일한 전체 데이터 집합에서 일반적으로 무작위로 선택되어야 합니다. 훈련training 범위에서 멀리 떨어진 입력을 기반으로 예측하려고 시도하는 경우 좋은 결과를 얻지 못할 수 있습니다.
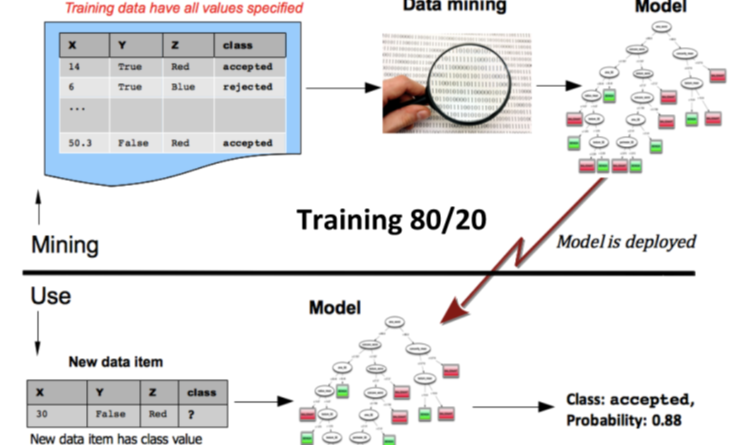
지도 머신러닝 모델은 일반적으로 입력 데이터의 일부를 사용하여 학습하고 나머지 부분으로 테스트합니다. 그런 다음이 모델을 사용하여 다음 다이어그램과 같이 새롭고 알려지지 않은 특성 값을 제공할 때 결과를 예측할 수 있는데 사용되어 질 수 있습니다:
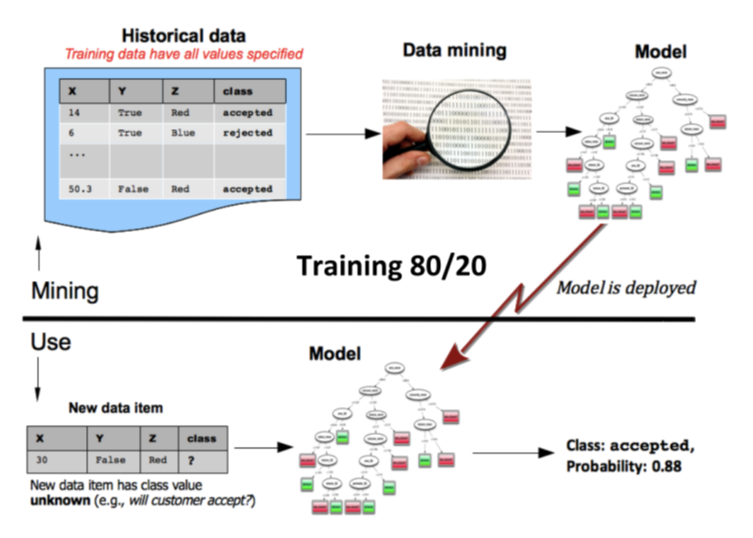
전통적인 지도 머신러닝 프로젝트는 다음의 단계를 포함합니다.
-
데이터 가져오기 및 다른 데이터 소스 병합(이 장의 다른 데이터 소스에서 엑셀로 데이터 가져오기Importing Data into Excel from Different Data Sources에서 자세한 내용을 설명할 예정)
-
데이터 정리(4장 데이터 정리 및 예비 데이터 분석Data Cleansing and Preliminary Data Analysis 참조)
-
예비 분석 및 특성 엔지니어링(5장 상관관계 및 변수의 중요함Correlations and the Importance of Variables 참조)
-
각각에 대해 서로 다른 모델과 매개변수 시도 및 전체 데이터 집합의 백분율을 사용하여 훈련하고, 나머지로 테스트 사용
-
소규모의 분리된 테스트뿐만 아니라 연속적인 분석 흐름에서 사용할 수 있도록 모델 배치
-
새로운 입력 데이터를 위한 값 예측
이 과정은 다음 장에서 보여지는 예제에서 명확해질 것입니다.
과소적합underfitting 과대적합overfitting의 비교
앞의 내용에서 4단계는 최적의 결과를 얻을 때까지 모델, 매개변수 및 특성을 시도하는 반복 프로세스를 의미합니다. 다음 다이어그램과 같이 정사각형을 원과 구분하려는 분류 문제에 대해 생각해 봅시다. 프로세스가 시작될 때, 첫 번째 차트(왼쪽)와 비슷한 상황에 있을 수 있습니다. 모형이 두 모양을 효율적으로 분리하지 못하고 양쪽 모두 정사각형과 원이 혼합되어 있습니다. 이를 과소적합underfitting이라고 하며 데이터 집합의 특성을 나타내는데 실패한 모델로 간주됩니다.
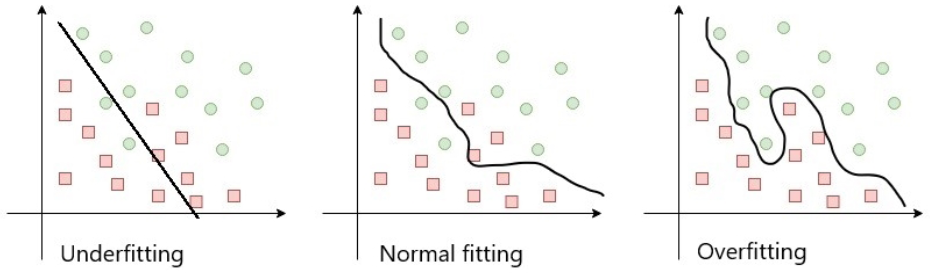
매개변수 조정을 계속하고 모델을 학습 데이터 집합에 맞게 조정하므로써 세 번째 차트(오른쪽)와 비슷한 상황에 처할 수 있습니다. 모델은 데이터 집합을 정확하게 분할하여 경계선의 각 측면에 하나의 모양만 남겨 둡니다. 이것이 정확해 보이더라도, 일반화는 완전하게 부족합니다. 결과는 훈련 데이터에 잘 맞게 조정되어 다른 데이터 집합에 대해 테스트하는 경우에는 완전히 잘못될 것입니다. 이 문제를 과대적합overfitting이라고 합니다.
모델에서 과대적합의 문제를 해결하기 위해서, 적응성adaptability을 높여야 합니다. 그러나 너무 유연하게 하면 예측이 나빠질 수 있습니다. 이를 피하기 위해 일반적인 해결책은 정규화regularization 기술을 사용하는 것입니다. 전문적인 문헌에서 찾을 수 있는 많은 유사한 기술이 있지만 이 책의 범위를 벗어납니다.
가운데 차트는 보다 유연한 모델을 보여줍니다. 데이터 집합을 대표하지만 이전에는 본적 없었던 새로운 데이터를 처리할 수 있을 정도로 충분히 일반적입니다. 좋은 머신러닝 모델을 만들기 위해서는 종종 시간이 많이 걸리고 적절한 균형을 잡기가 어려울 수 있습니다.
모델 평가Evaluating models
결과를 얻을 때마다, 이것은 실제의 문제를 대표하는 모델만큼 정확합니다. 따라서 모델의 성능을 평가하는 데 사용할 수 있는 방법을 이해하는 것이 매우 중요합니다.
분류 모델classification models을 다루는 경우 다음 방법을 사용할 수 있습니다.
분류 정확도 분석Analyzing classification accuracy
이것은 전체 샘플수에 대해안 정확한 예측correct predictions (CP)의 비율입니다.
Accuracy = CP / TP
여기서 CP는 정확하거나 올바른 예측 수이고, TP는 모든 예측의 총 수입니다.
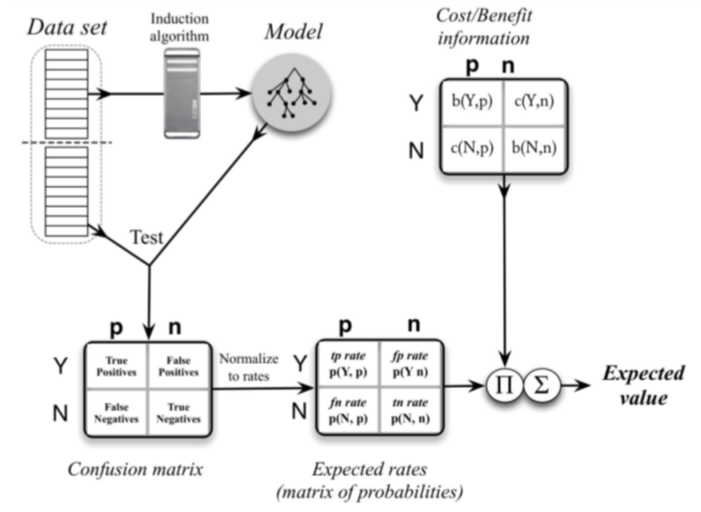
혼동행렬의 작성Building the confusion matrix
이제 이진 분류 문제에 대해 생각해 봅시다. YES 또는 NO의 두 클래스에 속하는 샘플 집합이 있습니다. 각 입력 집합의 변수에 대한 클래스를 출력하는 머신러닝 모델을 구축할 수 있습니다. 200개 샘플에서 모델을 테스트함으로써 다음과 같은 결과를 얻을 수 있습니다.
|
N=200 |
예측 NO |
예측 YES |
|
실제 NO |
60 |
15 |
|
실제 YES |
25 |
100 |
혼동행렬에는 4가지 요소가 존재합니다.
-
True positives (TP): 모델이 YES라고 예측하고, 실제 값도 YES인 횟수. 우리의 예제에서 이것은 100번이다.
-
True negatives (TN): 모델이 NO라고 예측하고, 실제 값도 NO인 횟수. 우리의 예제에서 이것은 60번이다.
-
False positives (FP): 모델이 YES라고 예측하고, 실제 값은 NO인 횟수. 우리의 예제헤서 이것은 15번이다.
-
False negatives (FN): 모델이 NO라고 예측하고, 실제 값은 YES인 횟수. 우리의 예제에서 이것은 25번이다.
그러면, 우리는 다음과 같은 식으로 혼동행렬을 계산한다.
Accuracy = (TP + TN) / N = (100+60) / 200 = 0.8
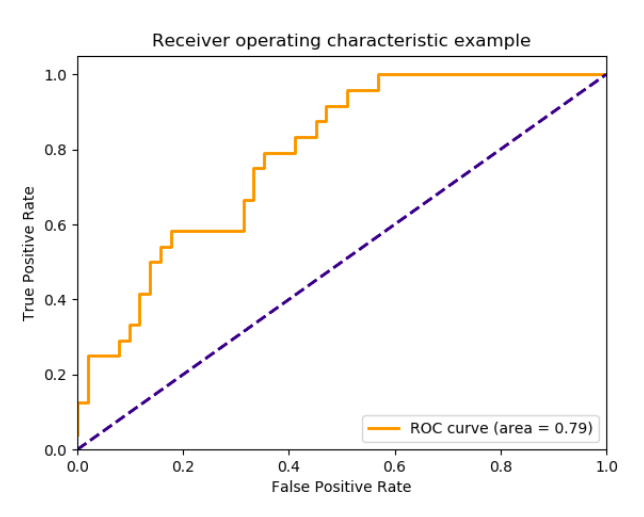
AUC 계산Calculating the Area Under Curve (AUC)
분류 모델의 AUC는 모델이 임의의 음성 예제보다 임의의 양성 예제가 순위가 높아질 확률로 정의됩니다.
혼동행렬을 사용하여 다음과 같이 다른 숫자를 정의할 수 있습니다.
TruePositiveRate =TP / (TP+FN)
True Positive Rate (TPR) 또는 민감도sensitivity는 실제 값이 YES인 모든 데이터 점들과 관련하여 올바르게 양성으로 예측된 데이터 점들의 비율입니다.
FalsePositiveRate =FP / (FP+TN)
False Positive Rate (FPR) or 특이점specificity 은 실제 값이 NO인 데이터 점들과 관련하여 잘못되게 YES로 예측된 NO 데이터 점들의 비율입니다.
두 숫자 모두 [0, 1] 범위의 값을 가집니다. FPR과 TPR은 서로 다른 임계값threshold으로 계산되고 그래프가 생성됩니다. 곡선은 수신작동특성Receiving Operating Characteristic(ROC)으로 알려져 있습니다. 다음 그림과 같이 AUC는 해당 곡선 아래의 영역입니다:
회귀 모델을 계산하려면 이 방법 대신에 다음의 기법을 사용할 수 있습니다.
평균절대오차(MAE)Mean Absolute Error 계산
MAE는 실제 값 (yj)과 예측 값 (ŷj)의 차이의 절대값의 평균입니다. 오차의 방향을 알려줄 수 없으므로 예측이 실제 값보다 높거나 낮을 수 있습니다. 총 N개의 데이터 점들이 있는 경우 다음과 같이 MAE를 계산할 수 있습니다.

평균제곱오차(MSE)Mean Squared Error 계산
MSE는 실제 값과 예측 값과의 차이의 제곱의 평균을 가집니다:
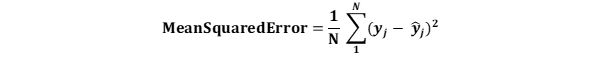
어떤 평가 방법을 선택하든, 문제에 대한 사업적인 부분을 고려하는 것이 매우 중요합니다. 최적의 솔루션은 항상 가장 정확한 모델이 아니라 사업적인 요구를 더 잘 충족시키는 모델입니다. 신속하게 구축할 수 있는 아주 정확하지 않은 모델이 개발하는 데 1년이 걸리는 완벽한 모델보다 낫습니다. 혼동행렬 값을 개선하기 위해 모델을 미세 조정하기 위해서는 데이터 집합의 불균형과 사업적인 요구를 고려하는 것이 중요합니다:
고려해야 할 또 다른 중요한 요소는 분류 문제의 경우 균형 잡힌 데이터 집합이 있는지 여부입니다. 지배적인 클래스로 인해 매번 동일한 결과를 주로 예측하는 모델로 이어질 것입니다. 예를 들어 99% YES 레이블을 가지는 데이터 집합은 입력의 99%에 대해 YES를 예측하는 학습에 따른 머신러닝 모델을 생성합니다(그리고 그것이 올바른 겁니다!). 데이터 집합의 균형을 맞추고 데이터에서 문제를 찾는 데에 사용도도록 알려진 기술이 많이 존재합니다.